機器學習:分析社會性別
議題
機器學習的演算法可能包含可觀的性別和族群偏見。在機器學習的管線中,偏見會存在哪裡:輸入的資料?演算法本身?或是運用的種類?更重要的是,人類該如何介入自動化的過程當中,以便促進,或至少不要傷害社會公平呢?而又是誰該做出這些決定呢?
很重要地,人工智慧正在打造未來(科技,也就是我們的裝置、程式以及程序形塑了人的態度、行為以及文化)。換句話說,人工智慧可能不小心將過往的偏見延續到了未來,即使政府、大學以及如Google或Facebook等公司都已經立定規範維護平等。那麼,大問題就在於:我們人類該如何能有效確保人工智慧支持社會正義?
方法:分析社會性別
社會性別涉及了文化態度與行為。人類透過習得的行為在龐大且複雜的社會中運作。我們說話的方式、我們的習性、我們使用的物品,以及我們的行為在在展現著我們是誰,也建立了互動的規則。社會性別便是這些行為與態度中的其中一套;族群則是另一套行為與態度。
社會性別包含了:
- 社會性別規範包含明說與未明說的文化規則(遍及立法規範的到無意識的規則),那是透過社會機構制度(例如家庭、學校、職場、實驗室、大學,或是董事會)以及更廣的文化產物(例如教科書、文學作品以及社會媒體)所產生的,而它影響了個體的行為、期望以及經驗。
- 社會性別認同意指個人或群體如何認知或展現自己,以及別人如何認知他們。社會性別認同是有可塑性的,可隨生命歷程改變,而且會依脈絡而定。社會性別認同可能會與其他身份認同相互交織,例如族群、階級或是性傾向,從而帶出多元的自我理解。
- 社會性別關係意指在家庭、職場以及整體社會中,不同性別認同的人之間的社會與權力關係。
性別化創新1:描繪出已知因科技而擴大的人類偏見案例
已知的性別偏見案例
- a.在Google搜尋中,男人被投放高薪行政工作廣告的機會比女人高出5倍(Datta, A. et al., 2015)。
- b.Google翻譯存在陽性預設。最先進的機器翻譯系統例如Google翻譯大量地濫用男性代名詞(he, him),即使內文指涉的是女人亦是如此。Google翻譯預設為陽性代名詞是因為「he(他)」在網路中比「she(她)」更為常見(比例為2:1)。這個社會性別偏見強化了社會性別不平等(Schiebinger et al., 2011-2018)。當一個翻譯程式的預設以「他說」來指稱女性,將會再度提高網路上陽剛代名詞出現的相對頻率,這可能會讓人類社會在性別平等的語言上得來不易的進程造成反轉。
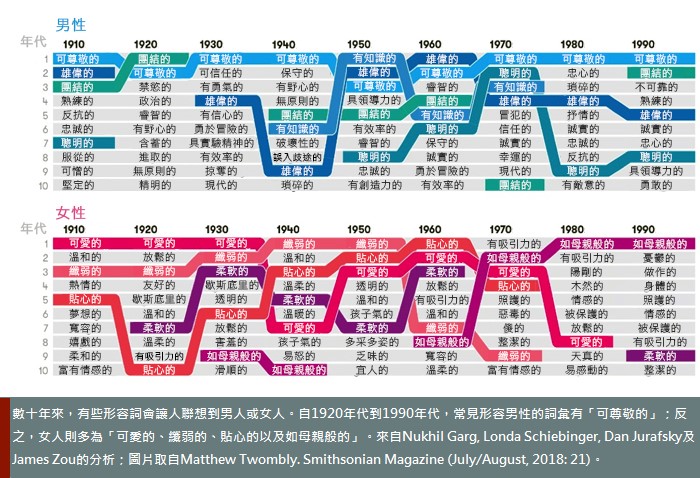
- c.詞向量(Word embedding)捕捉詞彙之間的關聯,這會有延續傷害性刻板印象的風險,例如「男人:電腦工程師 :: 女人:家管」(Bolukbasi, T. et al., 2016)。詞向量是種備受歡迎的機器學習方式,它將每個英語單字繪製成幾何向量,而向量間的距離則捕捉了對應字詞的詞義相似度。向量能成功捕捉出類推關係,例如男人對應國王、女人對應皇后。然而同樣的向量也會產出男人對應醫師、女人對應護理師以及男人對應電腦工程師、女人對應家管的結果。放任不管的話,我們可能會永遠活在1950年代。
已知的族群偏見案例方法:交織性研究方法
分析生理與社會性別固然重要,但其他重要的因子也會與生理和社會性別交織。這就是學者所稱的「交織性」。這些因子或變因可能是生物性的、社會文化的、或是心理性的,同時也可能包括:年齡、障礙、族群、國籍、宗教信仰、性傾向等等。
- a.美國法院使用的軟體似乎較容易將黑人被告(相較於白人)標誌為未來再次犯罪的高風險群—請見以下對於定義公平的討論(Angwin, J., & Larson, J. 2016),以及這份論文提出的解決辦法(Kleinberg et al., 2017)。
- b.搜尋可辨為黑人的名字時,出現內含「逮捕」一字的廣告次數比起搜尋可辨為白人的名字時更頻繁,且無論被搜尋者有無被捕紀錄皆然(Sweeney, 2013)。
- c.Nikon的相機軟體設計若拍攝對象在眨眼就不會拍下照片,卻將亞洲人的影像誤讀為一直眨著眼睛。
- d.研究人員將卷積神經網路應用於以照片辨識皮膚癌,他們以內含超過128萬張影像的數據集來訓練該模組,而其中60%是來自Google Image刪除的影像(Esteva et al., 2017)。但是這些影像僅有不到5%是深膚色的人,且演算法亦未以深膚色者進行測試過。因此該分類器的表現在不同人口之間可能有很大程度的差異。
- e.預測性模組在基因醫療應用的增加也突顯了數據不平等的危險。在2016年時,超過80%的基因數據都是從歐洲血統的個體中蒐集得來的。這代表著那些疾病風險預測器在遇到非歐洲人口時可能會明顯失效。而確實,非洲血統的患者比歐洲血統的患者更有機會被誤診為有可能會罹患肥厚性心肌症—一種致命的心臟問題—的基因風險(Popejoy & Fullerton, 2016)。
- a.商用臉部辨識系統在辨識深膚色女性時,認錯性別的比例遠遠高出其辨識淺膚色男性之時,錯誤率為35%比0.8%—解決方法亦請見下文(Buolamwini & Gebru, 2018)。
性別化創新2:描繪出解決之道
打造訓練數據集以避免偏見

- a.有幾個研究團隊正積極設計包含詮釋資料和「營養標籤」的機器學習數據集「規格單」(Gebru et al., 2018; MIT Media Lab, 2018)。雖然詮釋數據的特定格式會依領域而異,但每個訓練組應附上數據是如何蒐集及註釋的相關資訊。包含人類資訊的數據應該統整參與者的組合樣貌數據,其社會性別與族群等等。透過群眾外包而來的數據標籤例如MS Turk,應包含群眾參與者的資訊,以及標籤時給予的指示。
- b.機器學習或神經資訊處理系統的同儕評閱期刊以及國際研討會應該對投件要求標準化的詮釋資料。人工智慧競賽平台例如Kaggle,以及數據資料庫例如OpenML,也應該這麼做。
- c.要蒐集更多樣的數據,突破便利分類也很重要—女人/男人、黑人/白人等,這就無法捕捉(跨)性別與族群身份認同的複雜性(Bivens, 2017)。
發展以演算法偵測及移除偏見的方式
當演算法可能存在偏見時,能夠偵測是很重要的。有幾個團隊正在為此研發工具。
- a.在一案例中,研究人員小心地規劃了一個社會性別與膚色表現型平衡的影像基準點數據集,並以膚色類型標示影像。接著他們使用此數據集評估商用性別分類器的準確性,得出結果的差異性如前述(Buolamwini & Gebru, 2018)。
- b.為了辨識前文所述的詞向量中的性別偏見,研究人員發展了幾何式技術,接著他們研發了一個用於去除此類向量中的偏見之演算法,例如「保母」與「祖父」和「祖母」間的距離一致(Bolukbasi, T. et al., 2016)。還有些研究人員將內隱連結測試應用在詞向量中,藉此示範其中包含了許多與人類相似的偏見(Caliskan et al., 2017)。另外還有些人則研發了GloVe的社會性別中立變項(Zhao, 2018)。以影像而言,研究人員首先展示了訓練演算法可能會強化訓練數據中出現的偏見,接著則研發了一項能降低此強化的技術(Zhao et al., 2017)。
- c.類似的技術也能用來研究整體社會中長久的刻板印象與偏見。研究人員在詞向量中運用幾何式公制,並以100年以上的文字數據加以訓練,藉此辨識歷史中社會性別與族群偏見的演變(Garg et al., 2018)。類似的方法亦能用於比較當今文件中的偏見。
這種偵測及減少偏見的技術在其他領域中也很需要,如刑事司法(例如被告的風險評估及假釋與否的決定,或做出判決時)、貸款與其他金融事務,以及聘僱之時。然而在這些領域中,必須仔細留心不正當的偏見之確切定義,以及各種減低技巧帶來的後果。這類的應用便是需要跨領域合作的研究範圍中的一部分,且此範圍正逐漸成長中。
- a.一個備受研究的方法是具體指出一個公平的定義,例如跨越族群亦能同樣精確的模型,並以此限制演算法使其依循該定義(Dwork et al., 2012; Hardt et al., 2016; Corbett-Davies et al., 2017)。很類似地,研究亦能後處理演算法的結果使其公平(Hébert-Johnson et al., 2017)。然而,在這些領域中要定義公平性,也已證實是個巨大的挑戰(Kleinberg et al., 2017)。
- b.進一步的挑戰是辨認出哪些族群應該受到保障,接著發展出一個對這些族群更公平的有效演算法。近期在人工智慧稽核上的努力已有了成效,能夠自動地辨別出演算法可能具偏見的子群體並將偏見加以減少。該稽核器本身就是個機器學習演算法,即使沒有顯見的個體性別/種族說明,亦能辨識偏見(Kim et al., 2018)。
性別化創新3:系統性的解決方法
當我們努力想提升數據與人工智慧中的公平性時,我們需要仔細思考公平的概念。舉例而言,數據應該要重現世界原本的樣貌,亦或重現我們期望中的世界—也就是達到社會公平的世界?該由誰來做這些決定?解決問題的電腦科學家與工程師?公司內的倫理團隊?政府的監察委員?若是由電腦科學家來做,他們該如何被教育?
要製作出能同時帶來高品質的技能與社會公平的人工智慧,需要幾個重要步驟,我們強調以下四點:
- 1. 關切基礎建設議題。意圖創造公平是很複雜的,必須理解偏見是如何鑲嵌在機構性的基礎建設以及社會權力關係當中(Noble, 2018)。除非細心研讀,否則結構性的偏見對社會行動者而言常是隱形的—無論是人類或是演算法。舉例而言,維基百科看起來是個很好的數據來源。其資料豐富,亦是全世界最常使用的網站第五位。但其中有些結構性問題:傳記類中女性的項目佔比不到30%,相關連結亦較常連至男性相關文章,且其中關於親密伴侶與家庭的內容也不成比例地高(Wagner et al., 2015; Ford & Wajcman, 2017)。這些不對等可能來自於全球維基百科編輯者中,女性的佔比僅不到20%(Wikimedia, 2018)。
- 2. 嚴謹的社會效益檢視。2017年阿西洛馬會議制定了23項人工智慧原則(https://futureoflife.org/ai-principles/)。我們現在需要為了達成這些原則,發展出檢視機制。Fairness, Accountability, and Transparency in Machine Learning(公平、可靠且透明化的機器學習https://www.fatml.org)便是以此為目標的機構。亦有幾項政府報告提及此議題(Executive Office of the President, 2016; CNIL, 2017)。
- 3. 打造跨領域且社會性多元團隊。新的倡議(機構)如史丹佛人類中心人工智慧機構;公平、可靠且透明化的機器學習組織;以及其他單位正集合了電腦科學家、律師、社會學家、人文學家、醫藥、環境與性別的專家組織跨領域團隊,希望優化人工智慧中的公平性。這種認知與社會的多元性也帶來了創意、發掘以及創新(Nielsen et al., 2017)。
- 4. 將社會議題融入電腦科學核心課程。電腦科學的學生畢業時應具備分析性別與族群及其工作更廣泛的社會影響之基本概念工具。我們建議將社會議題融入電腦科學核心課程—大學與研究所層級皆然—搭配演算法的介紹。
結論
人工智慧已準備改造經濟與社會、改變我們溝通與工作的模式,並且重新形塑治理與政治。我們人類創造出了持續已久的社會不平等;有了新的工具,我們將有機會在文化中及跨文化間打造公平性,並藉此提升全球女性、男性以及性別多元者的生活品質。
備註:此案例研究中的部份素材汲取自Zou & Schiebinger (2018)。
參考資料
Angwin, J., & Larson, J. (2016, May 23). Bias in criminal risk scores is mathematically inevitable, researchers say. Propublica https://www.propublica.org/article/bias-in-criminal-risk-scores-is-mathematically-inevitable-researchers-say
Bivens, R. (2017). The gender binary will not be deprogrammed: Ten years of coding gender on Facebook. New Media & Society, 19 (6), 880-898.
Bolukbasi, T., Chang, K. W., Zou, J. Y., Saligrama, V., & Kalai, A. T. (2016). Man is to computer programmer as woman is to homemaker? Debiasing word embeddings. Advances in Neural Information Processing Systems, 4349-4357.
Buolamwini, J., & Gebru, T. (2018). Gender shades: Intersectional accuracy disparities in commercial gender classification. Conference on Fairness, Accountability and Transparency, 77-91.
Caliskan, A., Bryson, J., & Narayanan, N. (2017). Semantics derived automatically from language corpora contain human-like biases. Science 356 (6334), 183-186.
Corbett-Davis, S., Pierson, E., Feller A., Goal S., & Huq A. (2017). Algorithmic decision making and the cost of fairness. Conference on Knowledge Discovery and Data Mining.
Commission Nationale Informatique & Libertés (CNIL). (2017). How Can Humans Keep the Upper Hand: Ethical Matters Raised by Algorithms and Artificial Intelligence. French Data Protection Authority.
Datta, A., Tschantz, M. C., & Datta, A. (2015). Automated experiments on ad privacy settings. Proceedings on Privacy Enhancing Technologies, 2015 (1), 92-112.
Dwork, C., Hardt, M., Pitassi, T., Reingold, O., & Zemel, R. (2012). Fairness through awareness. Proceedings of the 3rd innovations in theoretical computer science conference, 214-226. ACM.
Esteva, A., Kuprel, B., Novoa, R. A., Ko, J., Swetter, S. M., Blau, H. M., & Thrun, S. (2017). Dermatologist-level classification of skin cancer with deep neural networks. Nature, 542 (7639), 115-126.
Executive Office of the President, Munoz, C., Director, D. P. C., Megan (US Chief Technology Officer Smith (Office of Science and Technology Policy), & DJ (Deputy Chief Technology Officer for Data Policy and Chief Data Scientist Patil (Office of Science and Technology Policy) (2016). Big Data: A Report on Algorithmic Systems, Opportunity, and Civil Rights. Executive Office of the President.
Ford, H., & Wajcman, J. (2017). ‘Anyone can edit’, not everyone does: Wikipedia’s infrastructure and the gender gap. Social studies of science, 47(4), 511-527.
Garg, N., Schiebinger, L., Jurafsky, D., & Zou, J. (2018). Word embeddings quantify 100 years of gender and ethnic stereotypes. Proceedings of the National Academy of Sciences, 115(16), E3635-E3644.
Gebru, T., Morgenstern, J., Vecchione, B., Vaughan, J. W., Wallach, H., Daumeé III, H., & Crawford, K. (2018). Datasheets for datasets. arXiv preprint arXiv:1803.09010.
Hardt, M., Price, E., & Srebro, N. (2016). Equality of opportunity in supervised learning. In Advances in neural information processing systems, 3315-3323.
Hébert-Johnson, U., Kim, M. P., Reingold, O., & Rothblum, G. N. (2017). Calibration for the (computationally-identifiable) masses. arXiv preprint arXiv:1711.08513.
Kim, Michael P., Amirata Ghorbani, and James Zou. Multiaccuracy: Black-Box Post-Processing for Fairness in Classification. arXiv preprint arXiv:1805.12317 (2018).
Kleinberg, J., Lakkaraju, H., Leskovec, J., Ludwig, J., & Mullainathan, S. (2017). Human decisions and machine predictions. The Quarterly Journal of Economics, 133 (1), 237-293.
Kleinberg J., Mullainathan, S., Raghavan, M., (2017). Inherent trade-offs in the fair determination of risk scores. In Proceedings of Innovations in Theoretical Computer Science (ITCS).
MIT Media Lab (2018). http://datanutrition.media.mit.edu
Nielsen, M. W., Andersen, J. P., Schiebinger, L., & Schneider, J. W. (2017). One and a half million medical papers reveal a link between author gender and attention to gender and sex analysis. Nature Human Behaviour, 1(11), 791.
Noble, S.U. (2018). Algorithms of oppression: How search engines reinforce racism. NYU Press.
Popejoy, A. B., & Fullerton, S. M. (2016). Genomics is failing on diversity. Nature, 538(7624), 161-164.
Prates, M. O., Avelar, P. H., & Lamb, L. (2018). Assessing gender bias in machine translation—a case study with Google Translate. arXiv preprint arXiv:1809.02208.
Schiebinger, L., Klinge, I., Sánchez de Madariaga, I., Paik, H. Y., Schraudner, M., and Stefanick, M. (Eds.) (2011-2018). Gendered innovations in science, health & medicine, engineering and environment, engineering, machine translation.
Shankar, S., Halpern, Y., Breck, E., Atwood, J., Wilson, J., & Sculley, D. (2017). No classification without representation: assessing geodiversity issues in open data sets for the developing world. arXiv preprint arXiv:1711.08536.
Sweeney, L. (2013). Discrimination in online ad delivery. Queue, 11(3), 10.
Wagner, C., Garcia, D., Jadidi, M., & Strohmaier, M. (2015, April). It's a Man's Wikipedia? Assessing Gender Inequality in an Online Encyclopedia. ICWSM, 454-463.
Wikimedia (2018), personal communication.
Zhao, J., Wang, T., Yatskar, M., Ordonez, V. & Chang, K.-W. (2017). Men also like shopping: reducing gender bias amplification using corpus-level constraints. arXiv preprint arXiv:1707.09457.
Zhao, J., Zhou, Y., Li, Z., Wang, W., & Chang, K. W. (2018). Learning Gender-Neutral Word Embeddings. arXiv preprint arXiv:1809.01496.
Zou, J. & Schiebinger, L. (2018). Design AI that’s fair. Nature, 559(7714), 324-326.

