機器翻譯:
分析社會性別
議題
性別化創新 1:研究機器翻譯中的男性預設
方法:分析社會性別
性別化創新 2:檢測實體指涉的社會性別以改善翻譯演算法
方法:重新思考研究優先次序與結果
性別化創新3:性別多元的翻譯
性別化創新4:將社會性別分析融入工程課程中
結論
議題
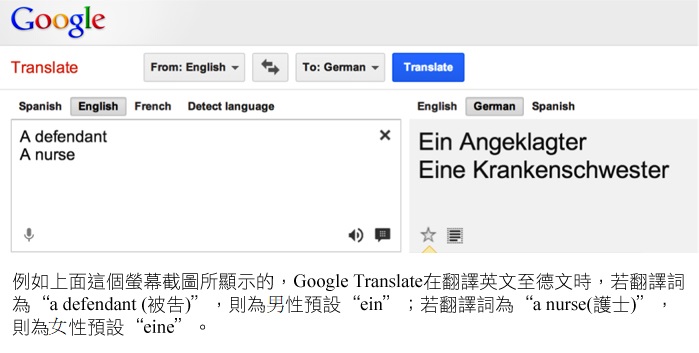
機器翻譯(MT)是自然語言處理(NLP)的一個重要領域,也是世界日漸全球化的關鍵應用。雖然機器翻譯的錯誤率仍高,然其正確性正在逐次改善。然而目前系統所產生的部分錯誤係來自根本技術挑戰,需要全盤根本的解決。其中一個問題就是社會性別:目前最先進的翻譯,例如Google Translate 或 Systran 都大量過度使用了陽性代名詞 (he, him),甚至在文本中實際指涉的對象是女性的時候也是如此 (Minkov et al., 2007)。其結果就是翻譯成果並不忠實而令人難以接受,以及社會性別偏見的延續。
這個問題在翻譯英文到其他語言或從其他語言翻譯到英文都有可能發生。尤其常見於翻譯低度性別屈折語言(如英語)至較高度的性別屈折語言(如印歐語言)時(Banea et al., 2008)。例如,在英語語句"a defendant was sentenced" (被告判刑)中,被告是男是女並不清楚。在將此句翻為德文時,此句需翻成兩種語句其中之一,一句指涉女性被告,一句指涉男性被告(Frank et al., 2004):
|
英文: |
德文: |
|
"A defendant was sentenced." |
"Ein Angeklagter wurde verurteilt." |
|
(被告的性別並未特別指定。) |
(被告指涉為男性,此為 或
"Eine Angeklagte wurde verurteilt." (被告指涉為女性。) |
人類可以利用文本脈絡(文件中前後語句)來確認被告的性別。而目前的機器翻譯系統卻無法利用前後語句,使得系統只能根據發生的頻率來選擇,亦即這個語句所指涉的性別在這個文本語料庫中發生的頻率哪一個比較高:"ein Angeklagter wurde" 或 "eine Angeklagte wurde"。在大部分的狀況下,結果都導致了男性預設,雖然也會有女性預設的情況。請參看以下圖表。
這個問題在翻譯其他語言到英文時也會發生。例如,西班牙文代名詞"su"可以翻譯成英文的"his (他的)" 或 "her (她的)"。這類問題經常發生在從常有代名詞省略的語言(代名詞脫落語言,如西班牙文、中文、日文)翻譯到如英文這類代名詞不省略的語言的時候。
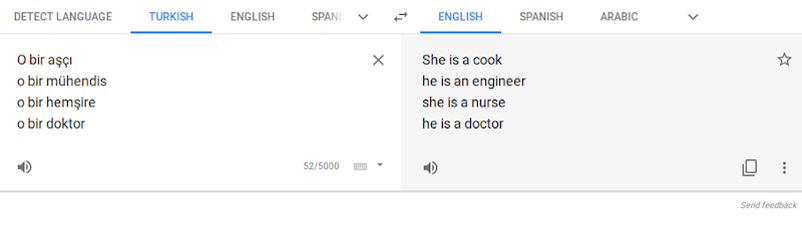
土耳其語則是另一個範例。性別中立的代名詞「o」被以反映著刻板預設的方式翻譯為英語中的「他」或「她」,例如:「她是廚師」、「他是工程師」、「她是護士」或「他是醫生」。 芬蘭語,愛沙尼亞語,匈牙利語和波斯語也是如此(Caliskan et al., 2017, supplement)。
性別化創新 1:研究機器翻譯中的男性預設
翻譯西班牙文成英文在現代機器翻譯軟體產生許多性別翻譯問題。其中一個原因是西班牙文是代名詞脫落語言。在翻譯成英文的時候,要使用什麼性別的代名詞就特別困難。例如,Londa Schiebinger曾在2011年3月接受西班牙報紙專訪。這篇訪問文章的英文翻譯就透漏出這些困難的各種徵兆-參見以下表格。
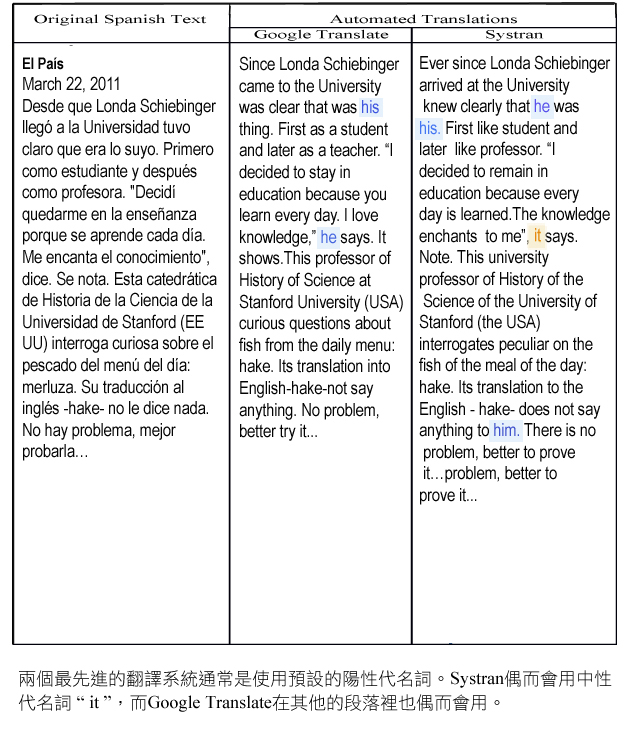
即使許多線索提示了文本裡面正確的性別,這些自動翻譯仍使用了錯誤的代名詞。例如:
-
"Londa"在英文裡是女性姓名,而且有列在線上人名表裡。
-
西班牙原文裡包含了性別屈折詞,例如"教授" (profesora, 陰性詞)與指明"Londa"為女性的描述詞"mujer" (女性)。
人類翻譯者可以利用來自文本脈絡的線索,明白下面的西班牙文文句:
-
"no le dice nada."
-
照字面讀成:
-
「沒有向他/她說任何事情」
-
西班牙字"le"(「他/她」)意思一定是「她」,而非「他」。
目前的機器翻譯系統沒有利用任何來自文本脈絡的線索。
方法:分析社會性別
機器翻譯系統在翻譯實體的正確社會性別的時候會有困難。其原因在於,目前的三個基本問題需要使用到人類讀者所依賴的性別線索。在這些方面機器翻譯系統還沒有解決:
- 人類翻譯者知道好的翻譯要保持原文的原始意義。
-
人類讀者在文本提到人類和這個人類所代表的事情時可以辨認出來,如性別。甚至在文本裡未明確提及這些事物時,人類也有能力可以辨認出來。例如在翻譯代名詞脫落語言中的無代名詞的動詞到英文這類的語言時,需要把它翻譯為有代名詞的動詞。人類翻譯者能夠瞭解這句話:
- "'Me encanta el conocimiento,' dice."
- 按照字面讀成:
- 「『我喜歡知識』,說」
- 指涉到表述了某件事的個人,所以應該翻譯成:
- 「『我喜歡知識』,她說」。
- 人類讀者依賴鄰近語句中交互指涉的名詞與代名詞所提供的資訊來理解語句。例如在第一句中所提到的"Londa"是這個專訪的受訪者一事,可讓人類讀者明白"suss trabajos" 或「她的/他的作品」指涉Londa的作品,因此所翻譯的代名詞須與Londa有相同的性別,並且應為「她的」,而非「他的」。人類讀者了解文本具有此類的一致性,不會在不同的句子裡隨機從這個人跳至那個人。人類翻譯者能理解所翻譯的來源語言中的交互指涉且在目標語言上產生相同的交互指涉。
目前的機器翻譯系統無法處理以下的三件事:
- 我們目前的系統所挑出的譯文,所根據的不是因為這個譯文跟原文有相同的意義,而是因為這個譯文使用到文句是人類翻譯者最可能會使用的字詞或語句。這些翻譯的規定雖然相似,卻不完全相同。
- 我們目前的系統不了解句中所指涉的人具有社會性別。這些系統完全不表示社會性別。
- 我們目前的系統並無計算交互指涉。目前系統使用文本脈絡的能力相當有限。翻譯的方式是用一次一句的形式進行,因此完全無法使用前句的訊息(像是所提及的"Londa")來協助隨後語句的翻譯。
我們相信我們現在已經可以解決這些問題 (參見以下論述的性別化創新2)。目前的機器翻譯系統所預設的代名詞是那些在所受訓練的文本語料庫中經常出現的代名詞。這些預設會很強勢——見下圖。
機器翻譯系統在兩類獨立的文本語料庫中訓練。一個是"平行語料庫",包含了用來源語言記載的文本以及所對應的目標語言的翻譯。另一個是大型單語語料庫,語料庫裡的語言是用來建模要翻譯的目標語言的語法。這兩類語料庫都可能產生代名詞性別錯誤。一個有關大型英文單語語料庫的研究指出,Google
Books語料顯示陽性代名詞在英文的頻率顯著比陰性代名詞多,雖然這個比例隨著時間而減低-參見下引圖表。這樣的偏差也許是導致上述專訪的翻譯中出現使用陽性代名詞來指涉女性受訪者的原因。
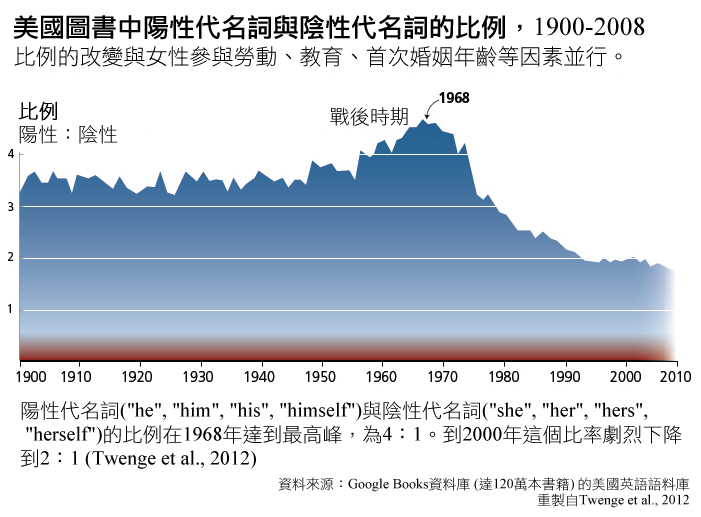
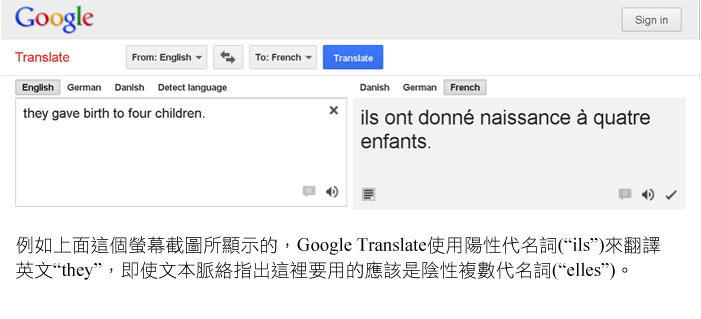
現在很多主要的公司與組織偏好或要求使用中立語言(Rose, 2010)。英文中"she or he"常用來指稱生理性別未知的人。通常使用複數人稱來重述句子可解決人稱參照的問題(參見:重新思考語言與視覺表徵)。因此,用「他(he)」作為通則的翻譯演算法已經跟現代代名詞的使用習慣脫節。
未能考量當前語言慣習的機器翻譯也造成了加劇性別不平等的風險。當翻譯程式的預設為「他說」時,網路上男性代名詞的出現便會增加。這可能會導致上圖所示的語言之正向平等趨勢產生長期、意料之外的反轉結果。
一項新的文獻回顧不僅聚焦於婦女相關的偏見,也聚焦非二元性別的人們,以克服該群體的「語言能見度(linguistic visibility)」(Kostikova, 2023)。
方法:重新思考研究優先次序與結果
這一類演算法還可以增進機器翻譯在翻譯富含人物角色的文類時的表現潛力(例如小說),這是目前的翻譯系統由於無法成功的針對一致性與交互指涉來創模,而無法達成目的的部份(Voigt et al., 2012)。
參考資料
Arnold, D., Sadler, L., & Humphreys, R. (1993). Evaluation: An Assessment. Machine Translation, 8 (1-2), 1-24.
Babych, B., & Hartley, A. (2003). Improving Machine Translation Quality with Automatic Named Entity Recognition. Proceedings of the 7th International Conference on Empirical Methods in Natural Language Processing (EMAT), Budapest, April 13
Banea, C., Mihalcea, R., Wiebe, J., & Hassan, S. (2008). Multilingual Subjectivity Analysis Using Machine Translation. Proceedings of the Association for Computational Linguistics 12th Annual Conference on Empirical Methods in Natural Language Processing (EMNLP), Honolulu, October 25-27.
Bergsma, S. (2005). Automatic Acquisition of Gender Information for Anaphora Resolution. Proceeding of Advances in Artificial Intelligence, 18th Conference of the Canadian Society for Computational Studies of Intelligence, Victoria, May 9-11.
Bergsma, S., Lin, D., & Goebel, R. (2009). Glen, Glenda or Glendale: Unsupervised and Semi-Supervised Learning of English Noun Gender. Proceedings of the 13th Conference on Computational Natural Language Learning, Boulder, Colorado, June 4-5.
Byron, D. (2001). The Uncommon Denominator: A Proposal for Consistent Reporting of Pronoun Resolution Results. Computational Linguistics, 27 (4), 569-577.
Chen, C. & Ng, V. (2012). Combining the Best of Two Worlds: A Hybrid Approach to Multilingual Coreference Resolution. Proceedings of the 24th International Conference on Computational Linguistics, Mumbai, December 8-15.
Frank, A., Hoffmann, C., & Strobel, M. (2004). Gender Issues in Machine Translation. Lingenio Gmbh, Heidelberg.
Fernandes, E., Nogueira dos Santos, C., & Milidiú R. (2012). Latent Structure Perceptron with Feature Induction for Unrestricted Coreference Resolution. Proceedings of the Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Korea, July 12-14, 41-48.
Hardmeier, C., Nivre, J.,& Tiedemann, J. (2012). Document-Wide Decoding for Phrase-Based Statistical Machine Translation. Proceedings of the Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Korea, July 12-14, 1179-1190.
Iida, R., & Poesio, M. (2011). A Cross-Lingual ILP Solution to Zero Anaphora Resolution. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, Portland, Oregon, June 19-24, 804-813.
Lee, H., Chang, A., Peirsman, Y., Chambers, N., Surdeanu, M., & Jurafsky, D. (2013). Deterministic Coreference Resolution Based on Entity-Centric, Precision-Ranked Rules. Computational Linguistics, 39(4).
Hovy, E., Marcus, M., Palmer, M., Ramshaw, L., & Weischedel, R. (2006). OntoNotes: The 90% Solution. Proceedings of the Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics, New York, June, 57-60.
Kong, F. & Zhou, G. (2010). A Tree Kernel-based Unified Framework for Chinese Zero Anaphora Resolution. Proceedings of the Conference on Empirical Methods in Natural Language Processing, Cambridge, Massachusetts, October 9-11.
Kostikova, A. (2023). Gender-neutral Language Use in the Context of Gender Bias in Machine Translation (A Review Literature). Journal of Computational and Applied Linguistics, 1, 94-109.
Minkov, E., Toutanova, K., & Suzuki, H. (2007). Generating Complex Morphology for Machine Translation. Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, June 23-30, Prague.
Momtazi, S., Faubel, F., & Klakow, D. (2010). Within and Across Sentence Boundary Language Model. Proceedings of Interspeech, Makuhari, Japan, September 26-30.
Ng, V. & Cardie, C. (2002). Improving Machine Learning Approaches to Coreference Resolution. Proceedings of Association for Computational Linguistics, Philadelphia, July, 104-111.
Pradhan, S., Ramshaw, L., Marcus, M., Palmer, M., Weischedel, R., & Xue, N. (2011). Conll-2011 Shared Task: Modeling Unrestricted Coreference in Ontonotes. Proceedings of the 15th Conference on Computational Natural Language Learning, Portland, Oregon, June 23-24,1-27.
Rose, L. (2012). The Supreme Court and Gender-Neutral Language: Setting the Standard or Lagging Behind? Duke Journal of Gender Law and Policy, 17 (1), 81-131.
Twenge, J., M., Campbell, W., & Gentile, B. (2012). Male and Female Pronoun Use in U.S. Books Reflects Women's Status, 1900-2008. Sex Roles, 67, (9-10), 488-493.
U.S. Social Security Administration. (2012). Popular Baby Names: National Data. Washington, D.C.: Government Publishing Office (GPO).
Vogel, A., & Jurafsky, D. (2012). He Said, She Said: Gender in the Association for Computational Linguistics Anthology. Proceedings of the ACL-2012 Special Workshop on Rediscovering 50 Years of Discoveries, Jeju Island, Korea, July 10, 33-41.
Voigt, R., & Jurafsky, D., (2012). Towards a Literary Machine Translation: The Role of Referential Cohesion. Proceedings of the North American Chapter of the Association for Computational Linguistics Workshop on Computational Linguistics for Literature, Montreal, June.
Zhao, S., & Ng, H. (2007). Identification and Resolution of Chinese Zero Pronouns: A Machine Learning Approach. Proceedings of Empirical Methods in Natural Language Processing and Computational Natural Language Learning Joint Conference, Prague, June, 541-550.
Zhou, G., & Su, J. (2004). A High-Performance Coreference Resolution System using a Constraint-based Multi-Agent Strategy. Proceedings of the 20th International Conference on Computational Linguistics, Stroudsburg, Pennsylvania.
幾年前我在馬德里接受幾家西班牙報紙的訪問。回家後,我用Google Translate來翻譯這篇訪談。我對於翻譯中以「他」來指稱我的事感到震驚。"Londa Schiebinger," 「他」說、「他」寫、「他」想。Google Translate以及在歐洲相對應的系統SYSTRAN都有男性預設。
像Google這樣「酷」的公司怎麼會犯這麼基本的錯誤?
Google Translate以陽性代名詞為預設是因為在網路上「他說」比「她說」更常出現。有趣的地方在這裡(參見以下圖示):
從NGram (Google另一產品)可以知道,陽性代名詞與陰性代名詞的比例從1960年代的4:1劇烈下跌到2000年的2:1。這個正好跟女性運動和大量政府資金的贊助女性參與科學研究等等事情相並行。Google由於一個翻譯演算法而抹除了四十年的語言革新,雖然他們並非有意如此。這是來自無意識的社會性別偏見。
性別化創新:
修正方法?性別化創新計畫於2012年七月舉辦了一場研討會。我們邀請了兩位自然語言處理專家,一位來自史丹佛 (Stanford),一位來自Google。他們聆聽了大約20分鐘後即明瞭問題所在。他們說:「我們可以修正這個問題。」 修正問題是很棒的,但不斷為女性改造並不是最好的進步途徑。事實證明,這是一個尚未解決的難題。為了避免將來出現這類問題,電腦科學家打從開始就具有性別意識是非常重要的。
重要的是,目前機器翻譯中的陽性預設可能會產生意料之外、長遠的後果。當翻譯程序預設為「他說」時,網路上出現的陽性代名詞就會增加(這將扭轉上圖所描繪語言平等的正面趨勢)。我們可能正在無意間建設一個強化性別不平等的未來。
一個更深層的解決辦法是將性別研究納入工程課程,這樣工程師未來就不會犯下這種錯誤。
