
機器發聲:
形成研究問題
議題:輔助文轉音系統(TTS)中的雄性預設
性別化創新 1:生成各式各樣男女聲音的文轉音技術
方法:重新思考研究優先次序與結果
方法:分析生理性別
性別化創新 2:了解話語中的社會性別
方法:分析社會性別
與生理/社會性別交織的因子:擴展話語資料庫
結論
下一步
議題:輔助文轉音系統(TTS)中的雄性預設
在歐洲與美國,文轉音系統主要用於兩方面:
為身障使用者設計的輔助文轉音系統:
文轉音系統可使緘默症及其他重度語言障礙患者透過轉換書寫文字成語音來進行口語溝通;也可以為視障者朗讀書籍、報紙、網站等內容 (Dutoit, 1997)。後者的功能對視障者特別重要,可讓這些患者有能力使用網際網路 (Pal et at., 2011)。消費產品中的人機界面:
如衛星定位系統 (GPS)經常使用TTS來「告知」駕駛者方向 (Berstis, 2001)。
早期輔助文轉音系統,如Votrax「Type’N’Talk」「無法生成雌性語音音高」(Walsh et al., 1986; Klatt et al., 1990)。這種雄性預設的現象在過往的語音合成中可能為無意識所導致的偏差,也可能是由於這個相關領域中的專業人士多為男性所致。而這個現象限制了使用者的自我表達。例如語音合成工程師Dennis Klatt所描述的案例:一位在車禍中受傷的年輕美國女性因為「談話輔助裝置讓她聽起來很陽剛而拒絕使用此裝置」(Klatt, 1987)。另一位腦性麻痺的年輕女性則表示,她因為僅能使用只有雄性語音的說話裝置而備感沮喪(Lupkin, 1998)。
性別化創新 1:生成各式各樣男女聲音的文轉音技術
成立於美國的迪吉多(Digital Equipment Corporation,簡稱「DEC」)在1984年開始銷售文轉音系統平台DECtalk(Leong, 1995)。DECtalk大部分的研發由Klatt所負責。他宣言,「給予使用者適切語音特徵的可能性,特別是給予婦女使用者女性化語音以及兒童使用者兒童化語音的優勢」,對提供輔助的宗旨而言,是「DECTalk的潛在優勢」(Klatt, 1987)。 DECTalk文轉音系統平台支援五種語音。雌性成人兩種,雄性成人兩種,兒童一種 (Turunen et al., 2004)。DECtalk的雌性與雄性語音是用明顯帶有成見的方式來呈現的。每種語音都以擬人化的方式對使用者用姓名來自我介紹。 「我是大個哈利」,雄性語音之一說道,「我是個大塊頭,有低沈的嗓門。我的 聲音給人權威感。」 」而雌性語音之一則說「我是細語溫蒂」,「我的說話帶著呼吸聲。我這樣竊竊私語你們聽得懂嗎?」這些聲音的樣本可在右邊的錄音片段中聽到(Klatt, 1987)。
女性與男性語音兩者很快成為文轉音系統的標準功能,例如蘋果電腦公司的MacInTalk Professional。重要的是,這些系統生成的雌性與雄性語音具有相似的辨識度(Rupprecht et al., 1995)—參見方法。
方法:重新思考研究優先次序與結果
歷史上語音合成以雄性語音為預設,限制了此技術的使用。工程師領悟到擴展語音的多樣性可開拓更多的文轉音系統使用者。關於女性與男性語音的比較研究因此而開始,來獲得人類語音潛在生理性別差異的知識-參見:分析生理性別。無論就人道或經濟觀點而言,製作聽起來逼真的雌性與雄性語音都十分重要。
見總方法
男女聲音有別。有力的證據包括聆聽者即使在缺少其他音聲與視覺線索的情況下,仍可準確辨認成人說話者的生理性別。這一類辨認不需要說話者與聆聽者有共通語言,也不須完整說出字句。例如,人類在聆聽單一母音聲音後辨認出發聲者生理性別的正確率高達98.9% (Whiteside, 1998) -參見方法。
方法:分析生理性別
生理性別差異可解釋部分(並非全部)女性聲音與男性聲音的差別。解剖學與生理學上的差異 – 諸如聲帶的大小與形狀,聲道長度,咽頭長度等等導致音調高低不同。女性聲音音調平均比男性聲音高,原因在於女性聲帶較短較輕,一般女性聲音基頻大約是「一般男性聲音基頻的兩倍」 (Simpson, 2009)。
見總方法
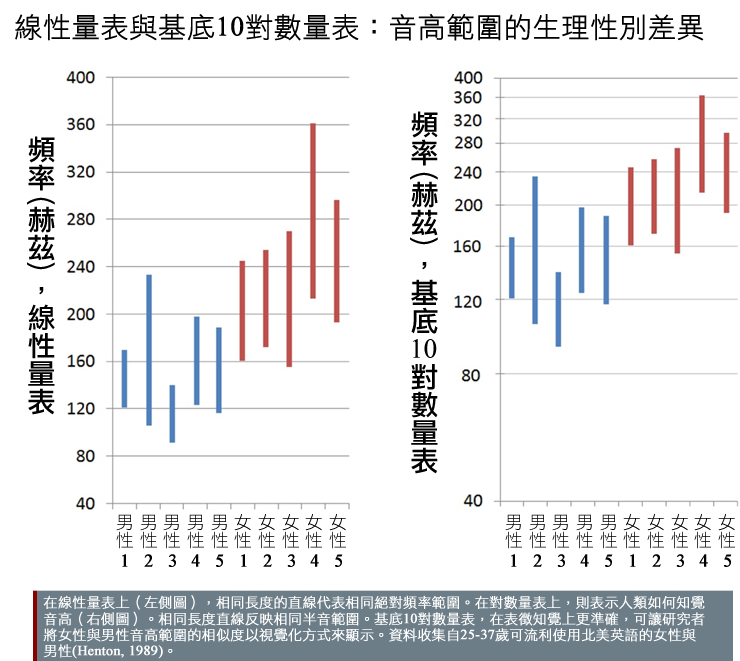
女性與男性音高範圍的比較取決於音高的定義。當女性與男性聲音以絕對音高範圍來比較,一般研究顯示女性的音高範圍比男性的音高範圍較廣。在歷史上有研究者就用這個來支持女性聲音屬於戲劇性、情緒性、激動而無理性等等的成見 (McConnell-Ginet, 1983)。而重要的是,以絕對音高範圍所作的比較並沒有反映在心理聲響學上。人類知覺音高的範圍並不是透過「量測絕對音高高低 (赫茲, Hz),而是用對數量表 (半音,semitone)來進行」(Henton, 1989)。 以半音來比較女性與男性聲音可知,雖然女性的絕對音高範圍比男性的絕對音高範圍廣,女性與男性在一般話語的半音範圍上卻相似。在這個情況下,以知覺精確的對數量表(而非線性量表)來比較女性與男性的音高範圍而重新思考語言和視覺表徵,則女性聲音為戲劇性與情緒性而男性聲音為單調冷靜的成見將受到挑戰 -參見圖表。
性別化創新 2:了解話語中的社會性別
社會性別對言談活動與聆聽活動(或詮釋聽到的話言)兩者皆有所影響,即使說話者是機器也是如此。語音涵涉諸多有關發言者的訊息,諸如生理性別、社會性別、年齡、甚或國籍,即使這類訊息從未直接表達出來。
社會性別與語音合成的關連在於其對人類話語的影響:創造具有「自然」雌性或雄性語音的文轉音系統編載了模擬女性語音或男性語音的生物特徵 (以生理性別為據)與文化特徵 (以社會性別為據)兩者。
方法:分析社會性別
研究顯示,社會性別信仰與行為對實際女性與男性語音特徵有所影響,於實際聆聽者對合成語音的反應亦然。
見總方法
- 分析分析社會性別規範:話語研究者在廣泛使用文轉音系統的很早之前,就已經體認到性別化行為會影響話語 (Fant, 1975)。話語音高在相當程度上是從文化期待學習而來,也受到文化期待的形塑。說話者可藉刻意降低說話音高獲得權威感。此行為在男性比女性更具社會性別正當性,然非僅局限於男性行使。以英國前首相柴契爾夫人為例,其曾受國家劇院的發聲教練訓練,降低其語音音高以使其更具權威感 (Atkinson, 1984)。
- 分析分析社會性別認同:語音編載社會認同的表達。對跨性別者的研究顯示部分跨性別者會調整其語音特質以求得與另一生理性別的語音特性相仿,強調個體改變其聲音以符合社會性別角色特徵的能力 (Gorham-Rowan et al., 2006)。
- 分析與生理/社會性別交織的因子:社會性別規範具有跨文化差異。以測量女性基本語音頻率與男性基本語音頻率為例,其結果顯示不同語言的說話者具有不同趨向。說法語的女性,其基本音高比說法文的男性高90赫茲,而說中文的女性,其語音音高僅比說中文的男性高10赫茲。研究者的結論認為「這個巨大的差異很難用受調查人口的解剖學上的差異來解釋」以及「部分差異須歸因於習得的行為」 (Simpson, 2009)。
 隨後,社會性別認同與規範乃編載於人類話語中。研究亦顯示,聆聽者會應用社會性別規範至語音合成上:
隨後,社會性別認同與規範乃編載於人類話語中。研究亦顯示,聆聽者會應用社會性別規範至語音合成上:
人類聆聽者會指派生理性別與社會性別給機器語音
;也就是說,他們會將機器說話者詮釋為女性或男性。人類聆聽者不喜歡機器語音在生理性別上混淆不清,甚至在完全了解聲音為機器發出時,即使所生成的聲音是「混淆」的,仍會為機器聲音指派生理性別。雖然指認的時間會比較長,也會改變指認的結果,聆聽者仍會嘗試替對這類聲音指派生理及社會性別,而非將「混淆」的聲音當成是生理性別中性的聲音。再者,聆聽者認為「混淆」的語音聽起來「奇怪、難以喜愛、不誠實、無知」 (Nass et al., 2005),使得這樣的聲音在輔助科技上、以及更廣泛的商業軟體上,都不受歡迎。聆聽者將有關性別的成見代入「雄性」或「雌性」的合成語音上。
而有關性別的成見又反過來影響了聆聽者對於所聽到語音所具有的競爭力、說服力、吸引力、誠信等等特徵的判斷。一份對美國9到11歲小學生所做的研究顯示,在刻板印象中認定為女性話題(例如皮膚保養、化妝品)的討論上,這些小學生認為雌性合成語音比雄性合成語音更讓人喜歡、更可信。而在刻板印象中認定為男性話題(例如足球)的討論上,雄性語音比雌性語音要更讓人喜歡、更可信(Lee et al., 2007; Niculescu et al., 2009)。研究結果反映了研究主題所提出的這些刻板印象與合成語音之間的交互影響。
聆聽者將社會性別成見代入合成語音的現象導致許多語音合成應用的基本問題。特別是依使用者偏好來調整語音合成與挑戰既定成見的目標有根本上的衝突。以汽車製造商BMW (Bayerische Motoren Werke) 為例,其原始隨車電腦上所使用的文轉音系統「說」的是雌性口音。可是部分購車者則拒絕「聽從」女性語音的導航指示。因此,替BMW開發文轉音系統的協力廠商在重新設計文轉音系統時,「決定將語音設定成帶有一些權威感、又多少是友善的、但高度勝任的雄性語音」(Nass et al., 2005)。此例顯示,滿足使用者對於文轉音系統的偏好會涉及對既定成見的順服,甚至提升。目前業者則提供消費者在雌性、雄性語音、各國語言與腔調上的選擇。
與生理/社會性別交織的因子:擴展話語資料庫
語音銜接合成法是一種文轉音系統製作方法,其運作方式是以預錄的自然人類語音片段予以連接整合。歐盟的HUMAINE計畫 (Human-Machine Interaction Network on Emotion project)率先支援先進的研究,擴展了歐盟區語言的語料庫(Roddie, 2010)。研究者自數量相同的德語及西班牙語女性與男性的錄音來建立語料庫 (Barra-Chicote et al., 2008; Burkhardt et al., 2005)。研究者還致力於製作不同語言與地方方言話語的合成語音。如西班牙的研究者製作了「兩套高品質語音,一為雌性,一為雄性」,支援「中加泰羅尼亞語 (Central Catalan dialect)、西班牙語、加利西亞語 (Galician),巴斯克語 (Euskera)和英語」的發音 (Bonafonte et al., 2009)。其他地方亦有相似的研究,著重於英語 (諸如不列顛、美國、澳洲、威爾斯、與南亞)、德語 (使用於德國與奧地利不同區域)、法語 (如瑞士與巴黎)等語言的腔調與方言 (Miller et al., 2011; Pucher et al., 2010; Yan et al., 2003; Sen et al., 2002)。
可模仿不同地域與社經區域方言的語音合成,同樣可能加深識別雌性或雄性話語的刻板印象。可合理懷疑聆聽者對於含有方言特色的語音合成,會用諸如種族、民族、社經地位、與地理區域等等成見來詮釋 (Pucher et al., 2009)。
結論
製作雌性合成語音是語音合成的一重要步驟,也協助開拓輔助文轉音系統的使用群。然而,製作「雄性」與「雌性」語音的能力卻也帶來加強社會性別成見的潛在可能。電腦文轉音系統是有效的社會行動者,它的信息傳遞仰賴底層的技術(如雌性與雄性語音的技術特徵)、運用 (如公司選用何種合成語音來代表一個產品)、與使用者的回應 (Lee, 2008)。
下一步
研究者致力於創造較靈活的不同語言與方言的語音合成器,來代表不同年齡、背景等的女性與男性。重要的發展包括:
創造情感話語:
人類的自然話語投射出說話者情緒狀態的訊息,且情感訊息「於語音合成上,因其自然、有效率和用途普遍,而頗具吸引力」 (Cahn, 1990)。然目前存有的商用文轉音系統,雖能生成相對清晰的語音,在情感交流方面卻頗為受限 (Rebordao et al., 2009)。具情感的文轉音系統是目前活躍的研究領域,可供輔助的用途 (如提供聲障者表達情感的能力),也可供商業用途(Gusikhin et al., 2011; Luneski et al., 2010)。更廣泛的說,可生成情感話語的電腦語音系統對可進行社交的機器人的發展頗為關鍵。發展個人化語音:
自然語音除傳遞生理性別、年齡、方言、情感狀態等訊息,也有鑒別人類說話者的獨特特點。輔助文轉音技術一般只提供固定語音,客製選擇甚少。研究者正致力於利用聲障者的「剩餘發聲能力」來創造清晰話語,以反映使用者諸如生理性別、社會性別等的身分特性(Jreige et al., 2009)。
參考資料
Atkinson, M. (1984). Our Masters' Voices: The Language and Body-Language of Politics. London: Methuen.
Barra-Chicote, R., Montero, J., Marcias-Guarasa, J., Lufti, S., Lucas, J., Fernandez-Martinez, F., Dharo, L., San-Segundo, R., Ferreiros, J., Cordoba, R., & Pardo, M. (2008). Spanish Expressive Voices: Corpus for Emotion Research in Spanish. Madrid: Universidad Politecnica de Madrid.
Berstis, V. (2001). Method and Apparatus for Displaying Real-Time Visual Information on an Automobile Pervasive Computing Agent. United States Patent 6,182,010. January 30.
Bonafonte, A., Aguilat, L., Esquerra, I, Oller, S., & Moreno, A. (2009). Recent Work on the FESTCAT Database for Speech Synthesis. Barcelona: Universitat Politècnica de Catalunya (UPC) Press.
Burkhardt, F., Paeschke, A., Rolfes, M., Sendlmeier, W., & Weiss, B. (2005). "A Database of German Emotional Speech." Proceedings of Interspeech/Eurospeech, 9th Biennial European Conference on Speech Communication and Technology, September 4—8, Lisbon.
Cahn, J. (1990). Generation of Affect in Synthesized Speech. Journal of the American Voice Input/Output (I/O) Society, 8, 1-19.
Dutoit, T. (1997). An Introduction to Text-to-Speech Synthesis. Netherlands: Kluwer Academic Publishers.
Fant, G. (1975). Non-Uniform Vowel Normalization. Kungliga Tekniska Högskolan (KTH) Department for Speech, Music, and Hearing Quarterly Progress and Status Report, 16 (2-3), 1-19.
Gorham-Rowan, M., & Morris, R. (2006). Aerodynamic Analysis of Male-to-Female Transgender Voice. Journal of Voice, 20 (2), 251-262.
Hasselbring, T., & Bausch, M. (2005). Assistive Technologies for Reading. Educational Leadership, 63 (4), 72-75.
Henton, C. (1989). Fact and Fiction in the Description of Female and Male Pitch. Language and Communication, 9 (4), 299-311.
Honorof, D., & Whalen, D. (2010). Identification of Speaker Sex from One Vowel across a Range of Fundamental Frequencies. Journal of the Acoustical Society of America, 128 (5), 3095-3104.
Jreige, C., Rupal, P., & Bunnell, T. (2009). "VocaliD: Personalizing Text-to-Speech Synthesis for Individuals with Severe Speech Impairment." Assets '09: The 11th international Association for Computing Machinery (ACM) Special Interest Group on Accessible Computing (SIGACCESS) Conference on Computers and Accessibility, October 25-27, Orlando.
Klatt, D., & Klatt, L. (1990). Analysis, Synthesis, and Perception of Voice Quality Variations among Female and Male Talkers. Journal of the Acoustical Society of America, 87 (2), 820-857.
Klatt, D. (1987). Review of Text-to-Speech Conversion for English. Journal of the Acoustical Society of America, 82 (3), 737-791.
Lee, E. (2008). Flattery May Get Computers Somewhere, Sometimes: The Moderating Roles of Output Modality, Computer Gender, and User Gender. International Journal of Human-Computer Studies, 66 (11), 789-800.
Lee, K., Liao, K., & Ryu, S. (2007). Children’s Responses to Computer-Synthesized Speech in Educational Media: Gender Consistency and Gender Similarity Effects. Human Communication Research, 33 (3), 310-329.
Leong, C. (1995). Effects of On-Line Reading and Simultaneous DECtalk Auding in Helping Below-Average and Poor Readers Comprehend and Summarize Text. Learning Disability Quarterly, 18 (2), 101-116.
Luneski, A., Konstantinidis, E., & Bamidis, P. (2010). Affective Medicine: A Review of Affective Computing Efforts in Medical Informatics. Information in Medicine, 49 (3), 207-218.
Lupkin, K. (1998). A Woman's Voice: Interview with Caroline Henton. Speech Technology.
McConnell-Ginet, S. (1983). Intonation in a Man’s World. In Thorne, B., Kramarae, C., & Henley, N. (Eds.), Language, Gender, and Society, pp. 69-88. Rowley: Newbury House.
Miller, J., Mondini, M., Grosjean, F., & Dommergues, J. (2011). Dialect Effects in Speech Perception: The Role of Vowel Duration in Parisian French and Swiss French. Language and Speech, Online in Advance of Print.
Nass, C., & Brave, S. (2005). Wired for Speech: How Voice Activates and Advances the Human-Computer Relationship. Cambridge: MIT Press.
Niculescu, A., van der Sluis, F., & Nijhot, A. (2009). "Femininity, Masculinity, and Androgyny: How Humans Perceive the Gender of Anthropomorphic Agents." Proceedings of the Thirteenth International Conference on Human-Computer Interaction, July 19th—July 24th, San Diego.
Pal, J., Pradhan, M., Shah, M., & Babu, R. (2011). "Assistive Technology for Vision Impairments: An Agenda for the Information Communications Technology and Development (ICTD) Community." 21st Annual Meeting of the International World Wide Web Conference Committee (IW3C2), March 28—April 1, Hyderabad, India.
Pucher, M. Schabus, D., Yamagishi, J., Neubarth, F., & Strom, V. (2010). Modeling and Interpolation of Austrian German and Viennese Dialect in Hidden Markov Model (HMM)-Based Speech Synthesis. Speech Communication, 52 (2), 164-179.
Pucher, M., Schuchmann, G., & Fröhlich, P. (2009). Regionalized Text-to-Speech Systems: Persona Design and Application Scenarios. Multimodal Signals: Cognitive and Algorithmic Issues, 5398, 216-222.
Rebordao, A., Shgaikh, M., Hirose, K., & Minematsu, N. (2009). "How to Improve Text-to-Speech (TTS) Systems for Emotional Expressivity." 10th Annual Conference of the International Speech Communication Association, September 6-10, Brighton.
Roddie, C. (2010). HUMAINE: Human-Machine Interaction Network on Emotion. Luxembourg: European Commission Publications Office.
Rupprecht, S., Beukelman, D., & Vrtiska, H. (1995). Comparative Intelligibility of Five Synthesized Voices. Augmentative and Alternative Communication, 11 (4), 244-248.
Sen, A., & Samudravijaya, K. (2002). Indian Accent Text-to-Speech System for Web Browsing. Sadhana, 27 (1), 113-26.
Simpson, A. (2009). Phonetic Differences between Male and Female Speech. Language and Linguistics Compass, 3 (2), 621-640.
Turunen, M., & Salonen, E. (2004). "Speech Interface Design." Tampere Unit for Computer-Human Interaction Speech Interface Design Workshop, September 13, Tampere, Finland.
Whiteside, S. (1998). Identification of a Speaker’s Sex: A Study of Vowels. Perceptual and Motor Skills, 86 (2), 579-584.
Yan, Q., & Vageshi, S. (2003). Analysis, Modeling and Synthesis of Formants of British, American and Australian Accents. Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing, 1, 712-715.
語音合成是指用機器產生人類話語的技術,可應用於語言學基本研究,協助身障人士的輔助科技,以及商業設備與軟體。
歷史上語音合成以雄性語音為預設,限制了此技術的使用。例如一位在車禍中受傷的年輕女性,拒絕使用只有雄性語音選項的談話輔助裝置。
性別化創新:
今日我們體認到生理性別(生物因素)與社會性別(社會文化因素)分析對於具有各種語音的文轉音系統的創造頗為重要,此具有各種語音的文轉音系統可用於各類輔助技術和其他人機介面。特別是社會性別的假設對於言談活動與聆聽活動(或詮釋聽到的話言)兩者皆有所影響,即使說話者是機器也是如此。
例如,社會性別認同與規範是編載於話語中的。如說法語的女性,其基本音高比說法文的男性高90赫茲,而說中文的女性,其語音音高僅比說中文的男性高10赫茲。研究者的結論認為“這個巨大的差異很難用受調查人口的解剖學上的差異來解釋”以及“部分差異須歸因於習得的行為”或社會性別規範。
聆聽者會應用社會規範於合成語音,且不喜歡機器語音在生理性別上混淆不清,使得這樣的聲音在輔助科技上,以及更廣泛的商業軟體上,都不受歡迎。再者,聆聽者在聽到「雄性」或「雌性」語音時,會傾向將社會性別成見附加在這個語音之上。公司有可能因為客戶的語音偏好而失去市場佔有率。如汽車製造商BMW即曾因導航系統提供雌性語音而被迫招回其生產的汽車。蘋果公司的iPhone手機所提供的Siri服務,最初是雌性iPhone助手,並未取得成功。
解決方法是提供消費者多樣選擇。研究者正致力於創造更靈活的機器來提供不同語言與方言,並具有代表不同年齡,社會性別認同,腔調,地理區域的女性與男性說話者的語音。
